What is Sentry?
Sentry is an open-source error tracking tool that helps developers monitor and fix crashes in real-time. It provides insights into the health of your applications by capturing and reporting errors, exceptions, and performance issues.Why integrate Sentry?
Integrating Sentry into your application allows you to:- Automatically capture and report errors and exceptions.
- Monitor the performance of your application.
- Gain insights into the user experience and identify bottlenecks.
- Improve the overall reliability and stability of your application.
Configuring Sentry
To integrate Sentry into your application, you need to initialize the Sentry SDK at the earliest instantiation point in your code. This ensures that Sentry starts capturing errors and performance data as soon as possible. Here’s how you can configure the Sentry SDK:Instrumenting your application
Vocode exposes a set of custom spans that get automatically sent to Sentry during Vocode conversations. To use these spans, you’ll need to manually attach a transaction to the current scope.Example 1: Streaming Conversation
Updatequickstarts/streaming_conversation.py, replace the main function with the following code:
Example 2: Telephony Server
Simply instantiate the Sentry SDK at the top of the file, e.g. inapp/telephony_app/main.py
Custom Spans Overview
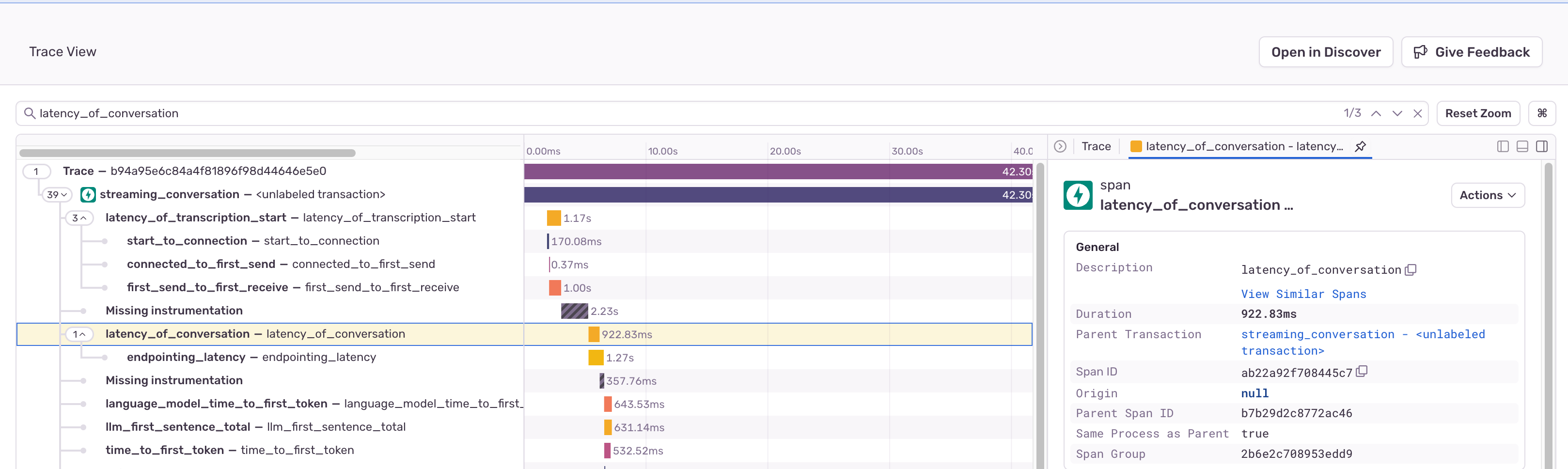
Latency of Conversation
Latency of Conversation (LATENCY_OF_CONVERSATION) measures the overall latency of a conversation, from when the user finishes their utterance to when the agent begins its response. It is broken up into the following sub-spans:
- [Deepgram Only] Endpointing Latency (
ENDPOINTING_LATENCY): Captures the extra latency involved from retrieving finalized transcripts from Deepgram before deciding to invoke the agent. - Language model Time to First Token (
LANGUAGE_MODEL_TIME_TO_FIRST_TOKEN): Tracks the time taken by the language model to generate the first token (word or character) in its response. - Synthesis Time to First Token (
SYNTHESIS_TIME_TO_FIRST_TOKEN): Measures the time taken by the synthesizer to generate the first token in the synthesized speech. This is useful for evaluating the initial response time of the synthesizer.
Deepgram
We capture the following spans in our Deepgram integration:- Connected to First Send (
CONNECTED_TO_FIRST_SEND): Measures the time from when the Deepgram websocket connection is established to when the first data is sent - [Deepgram Only] First Send to First Receive (
FIRST_SEND_TO_FIRST_RECEIVE): Measures the time from when the first data is sent to Deepgram to when the first response is received - [Deepgram Only] Start to Connection (
START_TO_CONNECTION): Tracks the time it takes to establish the websocket connection with Deepgram
LLM
For our OpenAI and Anthropic integrations, we capture:- Time to First Token (
TIME_TO_FIRST_TOKEN): Measures the time taken by the language model to generate the first token (word or character) in its response. - LLM First Sentence Total (
LLM_FIRST_SENTENCE_TOTAL): Measures the total time taken by the language model to generate the first complete sentence.
Synthesizer
For most of our synthesizer integrations, we capture:- Synthesis Generate First Chunk (
SYNTHESIS_GENERATE_FIRST_CHUNK): Measures the time taken to generate the first chunk of synthesized speech. - Synthesizer Synthesis Total (
SYNTHESIZER_SYNTHESIS_TOTAL): Tracks the total time taken for the entire speech synthesis process. This span helps in understanding the overall performance of the synthesizer.
ElevenLabsSynthesizer, the span SYNTHESIZER_SYNTHESIS_TOTAL will be recorded as ElevenLabsSynthesizer.synthesis_total:
- Synthesis Total (
SYNTHESIZER_SYNTHESIS_TOTAL) - Time to First Token (
SYNTHESIZER_TIME_TO_FIRST_TOKEN)